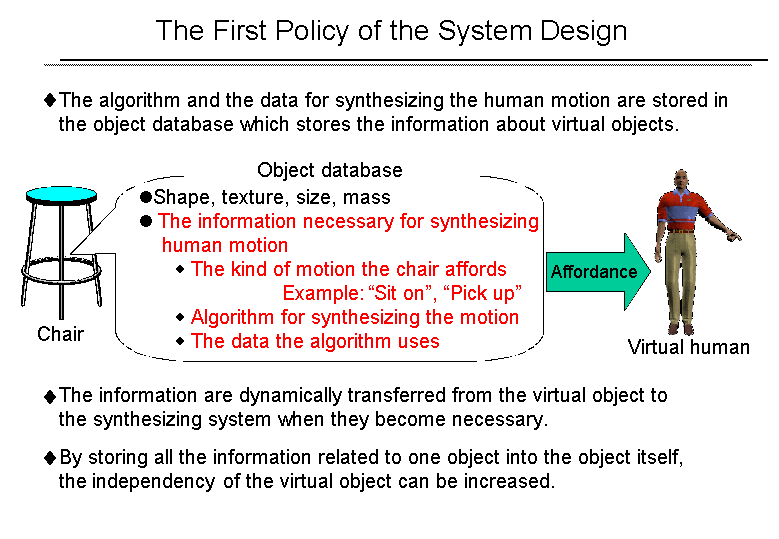
When this way of thinking would apply to the development of the human motion synthesizing system, the algorithms and the data for synthesizing the virtual human's motion should be composed not in the virtual human's brain but in the virtual objects located in the virtual environment. And the algorithms and the data should be transferred from the virtual object to the synthesizing system at the time when they become necessary.
For example, a floor affords "walk-on-ability" to the virtual human if the floor is large enough and smooth enough. In this case, the algorithms and the data for synthesizing the walking motion should be composed not in the synthesizing system but in the database which describes the information about the floor. In other words, the necessary information for synthesizing the virtual human's motion should not be composed in the synthesizing system but in the database which describes the information about the virtual objects such as the 3 dimensional shape, texture and so on.
Based on the discussions mentioned above, we made it the first policy of the system design that the algorithms and the data necessary for synthesizing the virtual human's motion are composed in the database not for the virtual human but for the virtual objects.
If the distance between a cup and a chair is short enough, a human can grasp the cup while sitting on the chair. In this way, a human can perform an action which relates to two different objects at the same time. But a human does not know how to perform an action toward all combinations of objects in the world. In this case, considering the basic concept of affordance, it could be interpreted as that both the cup and the chair afford the motion "grasp a cup" and the motion "sit on a chair" respectively, and the both affordances are mixed together into the one affordance "grasp a cup while sitting on a chair".
To make it possible to synthesize the mixed motion with the AHMSS, we supposed that a human does not accept the affordance uniformly; the degree of the affordance intensity varies according to every part of the human body. For example, a cup affords the motion "grasp a cup" strongly toward the arm while weakly toward the other part of the body. And a chair affords the motion "sit on a chair" strongly toward the legs and the hip while weakly toward the rest. If the distance between a cup and a chair is short enough, a human accepts the affordance from both of the cup and the chair. And because the degree of the affordance intensity from the cup is stronger than that from the chair, the arm performs the action "grasp a cup". Likewise, because the degree of the affordance intensity from the chair is stronger than that from the cup, the legs and the hip performs the action "sit on a chair". All together, the human acts "grasp a cup while sitting on a chair".
Based
on the concept of mixing of affordances as mentioned above, we made it
possible to synthesize the mixed motion with the AHMSS. Concretely, we
introduced the concept of the motion weight. The motion weight is the numerical
value which represents the priority of the human motion over the other
motion and it is set to each joint of human's body. In the AHMSS, the motion
weight is prepared to every action the virtual objects can afford.
